![]() آرش غفوری ۱۶ اردیبهشت ۱۳۹۹
آرش غفوری ۱۶ اردیبهشت ۱۳۹۹

از اولین روز اعلام وجود بیماری کووید-۱۹(از طریق ویروس کرونا) در ایران، دو پرسشِ بیپاسخ همواره مطرح بوده است: این ویروس از چه زمانی وارد ایران شد؟ و رقم واقعی مبتلایان چقدر است؟ در این مقاله توضیح میدهم که تعداد مبتلایان به ویروس کرونا در ایران تا روز هفت اردیبهشت حداقل ۲۲۰ هزار نفر است. آمار رسمی در این روز تعداد کل مبتلایان را حدود ۹۰ هزار نفر اعلام کرده بود. همچنین با یک حساب و کتاب ساده، از تعداد افراد بهبودیافته در روزهای مختلف طبق آمار رسمی، به این نتیجه میرسم که اولین موارد ابتلا به این بیماری حداقل باید در هفته اول بهمن سال ۱۳۹۸ رخ داده باشند.
در این مقاله، گزارشهای رسمی توسط وزارت بهداشت را بررسی میکنم و ایرادها و موارد قابل بحث آن را توضیح میدهم. در عین حال برای تحقیق در مورد دو سئوال اصلی این تحلیل، به این پرسشِ ناخواسته هم پاسخ میدهم که چه متغیرهایی، میزان مبتلایان به ویروس کرونا در هر استان را تبیین میکنند. برای شروع بحث، از نکته آخر شروع میکنم، چون اگر بدانیم آمار مبتلایان به ویروس کرونا در هر استان چگونه و منطبق بر چه متغیرهایی قابل تحلیل است، آنگاه میتوانیم برآورد دقیقتری از مبتلایان استان هم داشته باشیم.
این توضیح را هم بدهم که آنچه که من در این مقاله به آنها استناد میکنم، تحلیل آماریِ دادههای ارائهشده توسط وزارت بهداشت در سطح ملی (تا روز سوم فروردین) و دانشکدههای علوم پزشکی در سطح استانی (تا ۷ اردیبهشت) است. گروهی به این دادهها تشکیک وارد میکنند و آنرا معتبر نمیدانند. فرض کنیم چنین ادعایی درست است؛ یعنی گزارشهای ارائهشده توسط وزارت بهداشت در مورد میزان مبتلایان و کشتهشدگان دارای حد معینی از خطا و کمتر از رقم واقعی است. اما آیا میتوان قاطعانه نتیجه گرفت که این دادهها ساختگی و محصول عددسازی هستند؟ در مورد دادههای استانی تا روز سوم فروردین من شواهد کافی که نشان دهد آمار ساختگی است نمیبینیم. برعکس، معتقدم که در آمار ارائهشده توسط وزارت بهداشت یک خطای سیستماتیک وجود دارد که به صورت همگن در کلِ کشور، آمار را کمتر از رقم واقعی برآورد میکند. در چنین حالتی اگر بتوانیم الگوهای رفتاری تعداد مبتلایان به ویروس کرونا را در ایران به تفکیک استانها در یک معادله آماری یا ریاضی توضیح دهیم، آنوقت با خوشهبندی استانها در گروههای همگن و یافتن یک یا چند استان که یافتههای جامعتری نسبت به بقیه دارند به عنوان استان(های) پایه، میتوانیم با تعمیم این آمار، برای پرسش مورد نظرمان – تعداد واقعی مبتلایان – جواب قابل دفاعی پیدا کنیم.
ما در وبسایت ۳۱ دادههای مبتلایان به ویروس کرونا را در ایران تا روز ۷ اردیبهشت بهروز کردهایم و در مورد آمار پس از این روز به دلایلی که در مقاله جداگانهای گفته شده است نمیتوانیم تحلیل آماری قابل دفاعی ارائه کنیم.
شهرنشینی، سن و تعداد تخت در بخش مراقبتهای ویژه
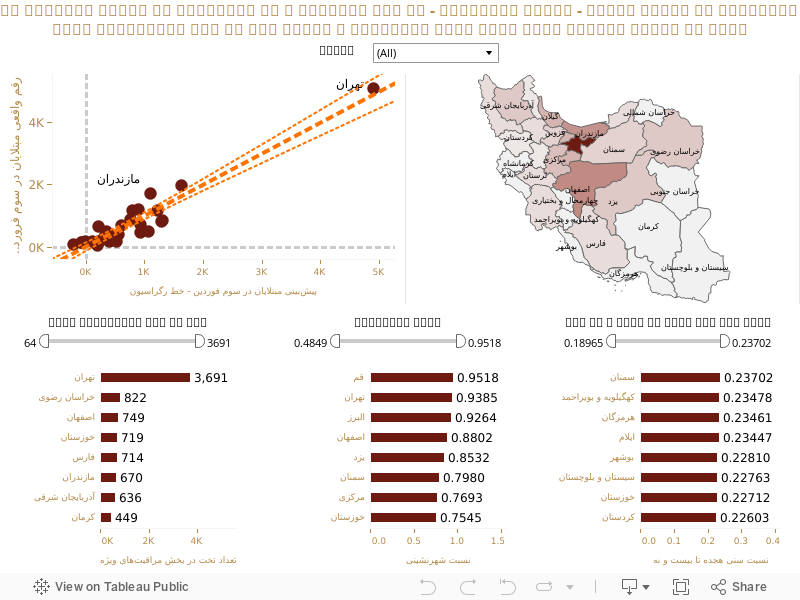
سه شاخص زیر، اصلیترین متغیرهای مستقلی هستند که در کنار یکدیگر میزان مبتلایان به ویروس کرونا را در استانهای مختلف ایران – بر اساس گزارشهای رسمی – تبیین میکنند:
– میزان تخت در بخش مراقبتهای ویژه در استان
– میزان شهرنشینی ساکنان استان
– نسبت افراد بین ۱۸ تا ۲۹ سال در استان
برای بدست آوردن اصلیترین متغیرهای موثر بر میزان مبتلایان به بیماری کووید-۱۹در هر استان، من بیشتر از ۳۰ متغیر شامل متغیرهای مبتنی بر ۱- بخش درمان (تعداد آزمایشگاهها، تختهای بیمارستانی، تختهای بخشهای مراقبتهای ویژه، تعداد درمانگاه، تعداد بیمارستان و …)، ۲- متغیرهای دموگرافیک (سن، جنس، نسبت ساکنان شهری و روستایی و …)، ۳- متغیرهای اقتصادی (تورم، بیکاری و …)، ۴- متغیرهای دیگر (مصرف مواد مخدر، میزان توریست و …) و ۵- یک متغیر برای در نظر گرفتن فراگیری در استانهای اولیه مانند قم، را در یک معادله رگراسیون چند متغیری مورد سنجش قرار دادم تا ببینم ترکیب کدام یک از این متغیرها، بیشتر از دیگران میتوانند توضیحدهنده آمار استانی مبتلایان به کرونا تا روز سوم فروردین – یعنی آخرین روزی که آمار مبتلایان به تفکیک استان ارائه شده است – باشند.
در این معادله رگراسیون چند متغیری، ۱- میزان تخت در بخش مراقبتهای ویژه (سیسییو و آیسییو)، ۲- میزان شهرنشینی ساکنان استان و ۳- نسبت افراد بین ۱۸ تا ۲۹ سال به کل جمعیت استان، سه متغیر اصلی و مستقلی بودند که ترکیب آنها با یکدیگر، بیشتر از هر ترکیب دیگری، توضیحدهنده تعداد کل مبتلایان به تفکیک استانها بود و تا حدود ۹۰ درصد آنرا تبیین میکرد. با این توضیح که رابطه بین دو متغیر اول و مقدار ابتلا به بیماری کووید-۱۹، مثبت است. یعنی به هر میزان که تعداد تخت در بخش مراقبتهای ویژه یا میزان شهرنشینی در یک استان بیشتر باشد احتمالا تعداد مبتلایان هم بیشتر است. اما رابطه متغیر سوم یعنی نسبت افراد بین بین ۱۸ تا ۲۹ سال با مقدار ابتلا به بیماری کووید-۱۹، منفی است. یعنی هر مقدار که نسبت افراد بین ۱۸ تا ۲۹ سال در یک استان بیشتر باشد، تعداد افراد مبتلا کمتر خواهد بود. در نمودارهای زیر میتوانید با انتخاب استان یا استانهای مختلف، وضعیت تعداد مبتلایان در سوم فروردین را با هر کدام از این سه متغیر به تفکیک استان بررسی کنید. همچنین با تغییر طیف اعداد مشخصشده برای هر نمودار میلهای، محدوده انتخابشده روی نمودار نشان داده میشود (اگر این مقاله را روی دستگاه تلفن همراهِ خود ملاحظه میکنید، از میان این سه متغیر فقط گزینه تعداد تخت در بخش مراقبتهای ویژه فعال است).
برای مشاهده دادههای خام و تحلیلهای آماری این مقاله میتوانید به صفحه گتهاب وبسایت مراجعه کنید. همچنین برای درک بهتر روشهای آماری استفادهشده در این مقاله و دلایل آن، بخش متدولوژی در بخش انتهایی این مقاله را بخوانید.
تعداد تستهای کرونا
با بدست آوردن اصلیترین متغیرهای مستقل در تبیین میزان مبتلایان به کرونا در هر استان، نوبت به یافتن متغیر دیگری میرسد که ۱- به تنهایی بتواند تبیینکننده میزان مبتلایان اعلامشده در هر استان باشد و ۲- بتواند در طبقهبندی و یافتن خوشههای همگن استانی به عنوان متغیر کمکی عمل کند. این متغیر، مقدار تستهای انجامشده در استانها برای یافتن مبتلایان به کروناست. ما میدانیم که تعداد مبتلایان در هر استان نسبت مشخصی با تستهای انجامشده در استان دارد، یعنی هر مقدار مبتلایان بیشتر باشد، تستهای انجامشده هم بیشتر است. اما مشکل اصلی در مورد تعداد تستها اینست که تنها در ۱۰ استان، تعداد کل تستهای انجامشده مشخص است. ما آمار کل تستها در سطح ملی را داریم اما در سطح استانی، دادههای ما منحصر به همین ۱۰ استان و آنهم در بازههای زمانی مختلف است. نسبت مبتلایان به تعداد کل تستها در این استانها متفاوت و بین ۹ تا ۴۸ درصد است.
برای بدست آوردن تعداد تستهای انجامشده (یا تستهایی که باید انجام میشده) در سایر استانها به سراغ متغیرهای قسمت قبل میرویم. به این معنی که استانها را بر اساس هر کدام از این متغیرها به صورت جداگانه (سن، شهرنشینی و تعداد تختهای بخش مراقبتهای ویژه) ابتدا به شش گروه خوشهبندی میکنیم به طوریکه تفاوت خوشهها به لحاظ آماری معنیدار باشد. در این حالت ما برای هر متغیر شش خوشه داریم که در هر خوشه استانهای همسان کنار یکدیگر قرار میگیرند. سپس استانها را بر اساس سه متغیر به صورت ترکیبی خوشهبندی میکنیم. اما این بار استانها را در پنج خوشه مجزا قرار میدهیم به صورتی که استانهای همگن در کنار یکدیگر قرار بگیرند و مانند قسمت قبل، تفاوت آنها به لحاظ آماری معنیدار باشد. دلیل تغییر تعداد خوشهها هم در این است که به غیر از استان تهران که به دلیل تعداد زیادِ مبتلایان رسمی در یک خوشه مجزا قرار میگیرد، سایر خوشهها حداقل شامل بیشتر از یک استان باشند.
در نمودار زیر میتوانید با انتخاب شماره خوشه مورد نظر، استانهایی که در خوشههای همسان قرار گرفتهاند ملاحظه کنید. همچنین در جدول پایین نمودار اطلاعات کاملی در خصوص هر استان، شماره خوشه مرتبط و متغیرهای مستقل متناظر با آن ارائه شده است.
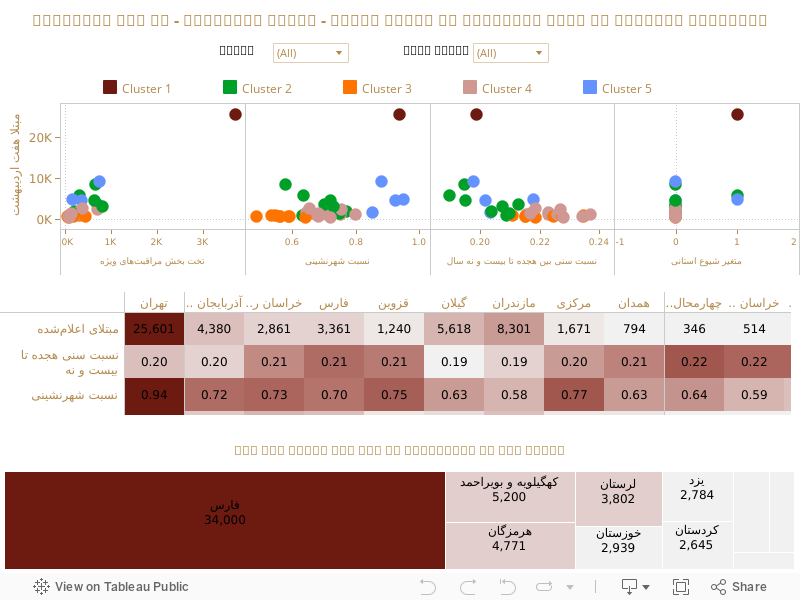
روش خوشهبندی (یا همان Clustering) در اینجا مبتنی بر الگوریتم ریاضی K-Means Clustering است (برای مشاهده دادههای خام و تحلیلهای آماری این مقاله میتوانید به صفحه گتهاب وبسایت مراجعه کنید. همچنین برای درک بهتر روشهای آماری استفادهشده در این مقاله و دلایل آن، بخش متدولوژی در بخش انتهایی این مقاله را بخوانید).
رقم واقعی مبتلایان: حداقل ۲۲۰ هزار نفر تا روز ۷ اردیبهشت
با داشتن ۵ خوشه مجزا شامل استانهای همگن در کنار یکدیگر، قطعات پازل ما برای بدست آوردن تعداد کل مبتلایانِ واقعی تقریبا تکمیلشده است. خوشههای همگن باید نسبتِ برابری از تعداد مبتلایان و تعداد تستهای انجامشده (یا تستهایی که باید انجام میشده) داشته باشند. در اینجا فقط نیاز داریم که ۱- مبنایی برای تعداد تستها در هر خوشه پیدا کنیم و ۲- یک استان یا چند استان را به عنوان استان(های) مرجع در نظر بگیریم و تعداد تستها و مبتلایان واقعی را در سایر استانها با آن(ها) بسنجیم.
برای بدست آوردن مبنای تعداد تستها در هر خوشه، میانگین رقم تستهایِ استانهایی که آمار آنها اعلام شده است را در هر خوشه در نظر میگیریم و برای اینکه نتایج، کمی محافظهکارانهتر هر باشد، در تعیین میانگین کل هر خوشه، رقم میانگین کل تعداد مبتلایان به تعداد تستها را هم که از آمارهای روزانه وزارت بهداشت قابل اندازهگیری است (چیزی در حدود ۲۱ درصد) در محاسبات خودمان منظور میکنیم. با ترکیب کردن این تعداد تستها در مدل و بر مبنای ۵ خوشه در نظر گرفتهشده برای استانها، تعداد کل تستهای ما بر اساس پیشبینیِ آمارِ رسمی چیزی در حدود ۴۴۱ هزار تست میشود که از مقدار کل تستهای اعلامشده (۴۲۰ هزار تا روز ۷ اردیبهشت)، حدود ۱۹ هزار تست بیشتر است (۴ درصد خطا).
برای تعیین استان مرجع هم از آمار استان فارس استفاده شده است. استان فارس از جمله استانهایی است که به صورت روزانه آمار تستهای انجامشده را اعلام میکند و تا روز ۷ اردیبهشت این رقم تقریبا برابر با ۳۴ هزار تست بود؛ یعنی تقریبا ۸ درصد تستهای کشور. اگر آمار استان فارس را مبنا در نظر بگیریم و با نسبت تعداد مبتلایان به تعداد تستها، آرای تستهای انجام شده (یا تستهایی که باید انجام میشد) را به تفکیک استانها مورد محاسبه قرار دهیم به عدد ۹۱۵۳۰۹ تست میرسیم. یعنی برای برآورد دقیقتر – و البته محافظهکارانه – از میزان مبتلایان به ویروس کرونا در ایران باید تا روز ۷ اردیبهشت، حدود ۹۱۵ هزار تست انجام میشد تا آمار واقعیتری از مبتلایان به ویروس کرونا در ایران بدست میآمد. در اینصورت بر اساس نسبت تعداد مبتلایان به تعداد کل تستها به تفکیک استانها، تعداد واقعی مبتلایان تا روز ۷ اردیبهشت حداقل ۲۲۰۷۲۶ نفر در کل کشور خواهد بود. همانطور که پیش از این توضیح داده شد، این رقم به گونهای محاسبه شده است که حداقلِ مبتلایان را به ما بدهد.
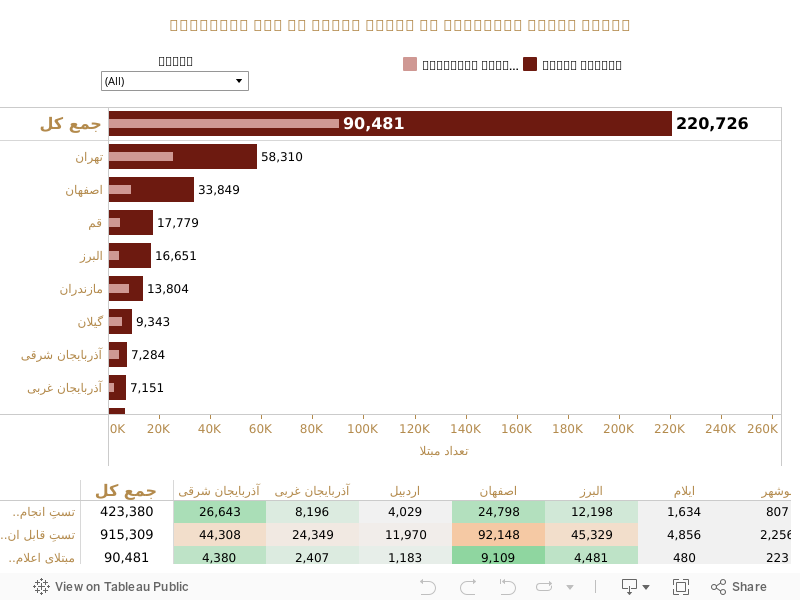
این توضیح هم قابل طرح است که در این تحلیل، من چند بار از عبارت “تستهایی که باید انجام میشد” استفاده کردم. دلیل این امر اینست که آمار روزانه وزارت بهداشت مبتنی بر تستهای قطعی مبتلایان است که در سه حالت ممکن است مخاطبان را گمراه کند. اول اینکه در بعضی از استانها، آمار روزانه مبتلایان که به صورت رسمی اعلام می شود از آمار تستهایی که نتایج آنها هنوز نیامده است تا چندین برابر کمتر است. دوم اینکه ما آمار زیادی از استانهایی داریم که در گزارش دانشگاههای علوم پزشکی آنها، یک طبقهبندی مشخص تحت عنوان بیماری حاد تنفسی ارائه میشود و رقم آن از آمار مبتلایان رسمی کرونا گاهی اوقات تا چهار یا پنج برابر بیشتر است. همچنین مواردی وجود دارند که تعداد افرادی که به علت ویروس کرونا در بیمارستانهای استان بستری شدهاند از میزان رقم اعلامشده برای مبتلایان به کرونا در استان بیشتر هستند. و سوم هم اینکه در برخی استانها، امکان تست روزانه محدود است و اساسا – حداقل بر اساس منابع رسمی – امکان تستگیری بیشتر از حد مشخصی وجود ندارد. در این حالت در نظر گرفتن آمار مبتلایان به کرونا بر اساس نتایج قطعی تستهای انجامشده از اساس گمراهکننده است.
کرونا از چه زمانی وارد ایران شده است؟
در مورد زمان ورود کرونا به ایران، طی یکی دو ماه اخیر، حرف و حدیثهای زیادی به صورت خبر منتشر شده است. ملاحظه من در این مقاله، بررسی اعتبار یا عدم اعتبار منبع، یا درستی یا نادرستی چنین روایتهایی، نیست. در اینجا من صرفا بر اساس آمار رسمی منتشرشده توسط وزارت بهداشت میتوانم بگویم که زمان ورود کرونا به ایران، حداقل یک ماه پیش از اعلام اولین گزارش رسمی مبتلایان به کرونا است.
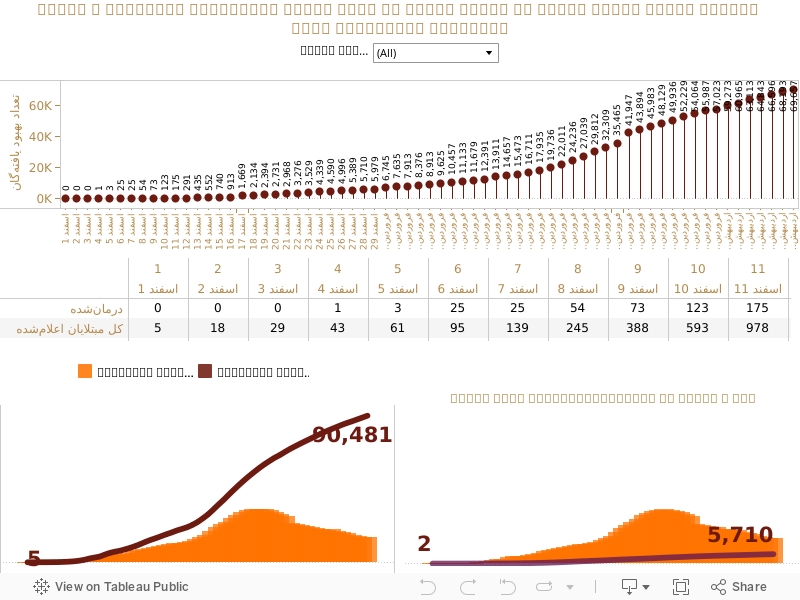
وزارت بهداشت شاخصی تحت عنوان “تعداد مبتلایان فعلی” (Active Case) را به صورت رسمی اعلام میکند و نتایج آن به صورت روزانه در وبسایت “ورد میتر” که در آن آمار مرتبط با کرونا در جهان بر اساس منابع رسمی کشورها منتشر میشود قابل دسترسی است. این رقم حاصل تفریق رقم فوتشدگان و رقم بهبودیافتهگان از تعداد کل مبتلایان است. یعنی اگر رقم فوتشدگان، آمار کل مبتلایان و تعداد مبتلایان فعلی (مبتلایان در یک روز مشخص) را داشته باشیم، میتوانیم تعداد بهبودیافتهگان (Recovered) را در روزهای مختلف بدست آوریم.
بر این اساس، اولین مورد بهبود یافته (Recovered)، برای روز چهارم اسفند سال گذشته ثبت شده است. در روز ۵ اسفند این رقم کلاٌ ۳ مورد (یک مورد در چهار اسفند و دو مورد در پنج اسفند) و در روز ۶ اسفند این رقم کلا ۲۵ مورد است. اگر دوره نهان این بیماری (حدود ۲ هفته)، مدت زمان انجام تست (در بهترین و خوشبینانهترین حالت، ۳ روز) و مدت زمان لازم برای بهبود آن (۲ هفته برای بیماران عادی و بین ۳ تا ۶ هفته برای موارد حادتر) را در نظر بگیریم، میتوانیم با اطمینان بالایی برآورد کنیم که اولین مورد ویروس کرونا در ایران حداقل بر اساس گزارشهای رسمی مربوط به هفته اول بهمن سال ۱۳۹۸ بوده است.
متدولوژی آماری
برای بدست آوردن اصلیترین متغیرهای موثر بر میزان مبتلایان به بیماری کووید-۱۹در هر استان، من بیشتر از ۳۰ متغیر را در یک معادله رگراسیون چندمتغیری مورد بررسی قرار دادم. نکته مهم در معادلههای رگراسیون این است که شما باید به عددی برسید که توضیحدهنده رابطه بین متغیرها در معادله باشند (R-Squared) که به آن نمره معادله میگوییم و عددی است که در بهترین حالت به صورت تئوریک، یک (۱) خواهد بود. در عین حال به هر میزان که تعداد متغیرها بیشتر شوند احتمالا تحت شرایط معینی، نمره معادله بیشتر خواهد شد. اما باید توجه کنیم که بر اساس پیشفرض در این نوع معادلات، ما نمیتوانیم از متغیرهایی که با یکدیگر رابطه آماری قوی دارند استفاده کنیم.
یعنی اگر تعداد تختهای بیمارستانی با تعداد تختهای بخشهای مراقبتهای ویژه در استانهای مختلف دارای رابطه آماری قوی است باید یکی از این دو متغیر انتخاب شود و نه هر دو. در معادله ما، اکثر متغیرهای بخش درمان با یکدیگر دارای رابطه آماری قوی بودند و انتظار هم همین است. یعنی به عنوان مثال اگر تعداد بیمارستان در یک استان بیشتر از استان دیگر باشد، انتظار بر این است که تعداد تخت بیمارستانی هم بیشتر باشد.
با این حال متغیری که بیشتر از سایر متغیرهای بخش درمان در ترکیب با متغیرهای دیگر در معادله ما، نمره بیشتری میگیرد تعداد تخت در بخش مراقبتهای ویژه است. این فرض کاملا پذیرفتهشدهای است که اگر تعداد تختهای مراقبتهای ویژه در استان بیشتر باشد، تعداد بیمارستانهای استان هم بیشتر است و به همین نسبت، تعداد آزمایشگاهها، کلینیکهای درمانی، تختهای عادی و موارد مشابه دیگر (آمار هم همین را نشان میدهد). این یافته، می تواند اولین قدم در بررسی تعداد واقعی مبتلایان در هر استان باشد. چرا؟
جواب ساده است. اگر استانی از لحاظ تجهیزات پزشکی و بهداشتی وضعیت بهتری دارد، یعنی فرضا تخت مراقبتهای ویژه در آن بیشتر است، انتظار میرود که امکان بررسی افراد بیشتری را از لحاظ تشخیص ابتلا یا عدم ابتلا به ویروس کرونا هم داشته باشد.
چنین روند ی برای انتخاب دو متغیر مستقل دیگر، یعنی افراد با سن ۱۸ تا ۲۹ سال و نسبت شهرنشینی در استان به کار گرفته شده است. با این توضیح که اگر شهرنشینی انتخاب شد و روستانشینی انتخاب نشد، یا نسبت ساکنان استان در سن بین ۱۸ تا ۲۹ سال انتخاب شده اما سن بالاتر از ۶۰ سال انتخاب نشد، دلیل آن این است که این دو متغیر در ترکیب با یکدیگر و همچنین در ترکیب با تعداد تختهای بخشهای مراقبتهای ویژه، نمره بیشتری در معادله بدست آوردند. ضمن اینکه به دلیل رابطه قوی آماری با یکدیگر، امکان استفاده از هر دو متغیر، مثلا شهرنشینی و روستانشینی به صورت همزمان، وجود نداشت.
در طبقهبندی استانها، من از روش خوشهبندی (یا همان Clustering) مبتنی بر الگوریتم ریاضی K-Means Clustering استفاده کردم که یکی از روشهای یادگیری ماشین به صورت نظارتنشده (Unsupervised Machine Learning) است و توسط بستهای با عنوان سایپای (SciPy) در زبان برنامهنویسی پایتان (Python) انجام شدهاست.
برای مشاهده دادههای خام و تحلیلهای آماری این مقاله میتوانید به صفحه گتهاب وبسایت مراجعه کنید.
چند نکته در مورد تحلیلهای آماری وبسایت ۳۱ که در تهیه این مقاله مورد استفاده قرار گرفته است:
- همانطور که در ابتدای این مقاله گفته شد، وزارت بهداشت از روز چهارم فروردین، ارائه آمار مبتلایان به ویروس کرونا را به تفکیک استان متوقف کرد. آنچه که ما طی روزهای ۴ فروردین تا ۷ اردیبهشت در مورد آمار استانی مبتلایان منتشر کردیم مبتنی بر مدلهای شبیهسازی موسوم به Exponential Smoothing و با سطح اطمینان ۹۵ درصد بر اساس اطلاعات مرتبط با آمار روزانه هر استان و ترکیب سه متغیر سن، شهرنشینی و تعداد تخت در بخش مراقبتهای ویژه، تا روز قبل از زمان ارائه گزارش است (برای مشاهده دادههای خام و تحلیلهای آماری این مقاله میتوانید به صفحه گتهاب وبسایت مراجعه کنید).
- بدیهی است که هر نوع مدل آماری و تحلیل دادهها مبتنی بر شبیهسازی و پیشبینی، دارای درصدی از خطا است و اساسا نمیتواند بدون خطا باشد. ما بر اساس تنظیم و به روزرسانی هر روزه مدل، سعی در کاهش این خطا داشتیم، اما در مورد احتمال و شیوه یا شیوههای خطاهای ممکن هم آگاه بودیم. به عنوان مثال اگر به هر دلیل، آمار مبتلایان روزانه در استانهایی که گزارش روزانه آنها منتشر نمیگردید، در یک روز خیلی بیشتر یا کمتر از معمول میشد، این امر در مدل شبیهسازی شده ما به مقدار واقعیِ تغییر، قابل اندازهگیری نبود. هرچند در برخی استانها مانند مازندران، تهران، سمنان و اصفهان، با اینکه تعداد کل مبتلایان اعلام نمیشد، آمارِ افزایش روزانه مبتلایان گاهی اوقات منتشر میگردید.
- خطای آماری وزارت بهداشت در کمتر اعلام کردن تعداد مبتلایان به ویروس کرونا در ایران در ابتدا یک خطای سیستماتیک بود که طی روزهای گذشته – حداقل از ۴ اردیبهشت – به عددسازی آماری رسید (در این مقاله به صورت کامل در این ارتباط توضیح داده شده است). در خطاهای سیستماتیک، چون میزان خطا به صورت همگن در استانهای مختلف صورت میگیرد، میتوان با بررسی الگوهای آماری و روندهای کاهشی یا افزایشی و در مواردی مانند مقایسه استانها با یکدیگر یا مقایسه تعداد مبتلایان یک استان در روزهای مختلف به نتایجی رسید که از لحاظ آماری قابل دفاع است. به عبارت بهتر، هرچند ممکن است مقدار واقعی نتایج (به عنوان مثال تعداد مبتلایان) درست نباشد، اما الگوهای رفتاری، به خصوص در سطح استانها قابل مقایسه و در نتیجه قابل تحلیل هستند. بر همین اساس، ما آمار تفکیکی کرونا را در سطح ملی و استانی تا هفتم اردیبهشت به صورت روزانه درصفحه ویژه کرونا منتشر کردیم که این تحلیل هم مبتنی بر همین آمار نوشته شده است.